| Aleks ihm sein Blog |
![[ Wir haben noch Hirn hinten im Haus ]](http://oerks.de/.blog/blogbild_sm.jpg)
Das ist mein Blog.
Hier gibts, was ich tue, getan habe und vielleicht tun werde. Auch, wenn und weil das total unwichtig für den weiteren Verlauf der Geschichte ist. Viel Spaß damit.
Wer mich möglichst zeitnah erreichen und/oder beschimpfen will, versuche dies per Email (s.u.), per Twitter, auf Facebook oder im ircnet oder suche mich persönlich auf.
-->
Einträge nach Kategorien
Einträge nach Datum
![[ blosxom ]](/.blog/pb_blosxom.gif)
![[ creative commons ]](/.blog/somerights20.png)
27.02.2013

01:46 Uhr Migration vom iPhone zum Nexus

Ich hab ein neues Hobby, bei dem man ähnlich wie beim Geocachen milliardenteure US-Militär-Satellitentechnik nutzt, um Tupperdosen im Wald oder eben virtuelle Items in der Stadt zu finden und mit diesen zu spielen. Dieses Spiel heißt Ingress und es geht um nicht viel weniger als die Weltherrschaft - wie das eben so ist. Dazu blogge ich bestimmt später noch mal was, bei Golem gabs heute nen kurzen Artikel dazu.
Für Ingress (die Betreiberfirma heißt Niantic, das spricht man aber wie 'google' aus) benötigt man ein Android-Handy, geht nicht mit nem iPhone - ein Schelm, wer böses dabei denkt... Ist bestimmt nur der beknackte Review-Prozess des iTunes-Stores und so, wissen schon.
Also hab ich mir ein altes Android-Handy geliehen, das schockt aber nicht - Ingress macht auch aus modernen Androids einen Taschenwärmer, weil es permanent 3D-Grafik-Berechnungen durchführt, GPS-Daten nutzt und eine Netzwerkverbindung aufrecht hält. Alte Androiden haben einfach nicht genug büms.
Vor ungefähr drei Wochen hab ich mir in einer Art von Gruppendruckhysterie ein Google Nexus4 bestellt, weil das preisgünstig und technisch auf dem Stand der Technik ist (und weil ich ne Meise habe, jaja).
Die Software-Migration war mit drei Ausnahmen problemlos:
- Ich benutzte bisher things um mich zu sortieren und nix zu vergessen. Der theoretische Hintergrund dazu wird bei Getting Things Done / GTD angerissen, ich erlebe es als große Hilfe, Dinge, die einmal im 'System' gelandet sind, nicht mehr vergessen zu können und diese umgekehrt auch erstmal bewußt ausblenden zu können. In der Praxis klopfe ich alles (alles[tm]) in die passende Anwendung rein, und zupfe es dann später auseinander, sortiere, fasse zusammen, strukturiere, terminiere, bla rabarber fasel. Um das tun zu können, brauche ich eine Anwendung, die lokal (ohne Netz) funktioniert, und zwar auf einem Gerät, daß ich immer dabei habe, also z.B. einem Handy - es reichen meist wenige Stichworte, um später daran weiter arbeiten zu können, ich mach das dann meistens am Computer, weil es übersichtlicher ist. Deswegen muß sich die Anwendung, so wie sie Netz spürt, mit allen Geräten, die ich benutze, synchronisieren können, um überall den gleichen Stand zu haben - ich will nicht von Hand dafür sorgen müssen, das die Stände stimmen. Als ich mit GTD angefangen habe (auf Papier, das geht auch :), gab es vor allem webbasierte Services (die verstiessen damals gegen die erste Forderung, das ist inzwischen kein Problem mehr) wie z.B. Remember The Milk, oder Insellösungen, die nur auf einem Device funktionierten. Things stach damals wohltuend hervor (konnte aber noch keinen cloud-sync, sondern nur Sync im gleichen Wlan), ging (und geht) aber nur auf iOS-Devices und aufm Mac - und war relativ teure Löhnware, aber es konnte alles, was ich mir vorstellen konnte und brauchte. Es gibt nen für mich brauchbaren, längeren Vergleich von GTD-Tools - nach dem Lesen und angleichen meiner eigenen NoGo-Kriterien bin ich bei Doit.im hängen geblieben und bin nur mässig begeistert, eventuell krempel ich das noch mal um.
- Der zweite Migrationsschmerz war eine Fahrtenbuch/Autokosten-Anwendung, deren Daten ich übernehmen wollte - ich hab das auch im leichten Fiberwahn mit den wahrscheinlich üblichen Schmerzen hinbekommen.
- Google hat mein sorgfältig gepflegtes Adressbuch angesaugt, runtergeschluckt, anverdaut, mit allen Google-Accounts (ich habe aus beruflichen und auch privaten Gründen leider einige) und deren total ungepflegten Contacts-Datenbanken vermischt, und wieder ausgespuckt. Nicht schön, aber ich hatte ein Backup und hab es im dritten Anlauf einigermaßen hinbekommen, welcher Google-Account wo wie das führende System sein darf.
Alles andere gibts genauso oder sehr ähnlich fürs Android, ein paar Konzepte sind anders, z.B. für Apples komplettes lokales Backup des kompletten Devices gibts keine Entsprechung, aber da ist nix, mit dem ich nicht schnell klarkommen würde - viele Dinge gefallen mir auch besser, einfach deshalb, weil es weniger Einschränkungen gibt. Man kommt z.B. einfach so ohne Gehumpfe ans Filesystem, kann beliebige mp3 als Klingeltöne verwenden und so weiter.
Die Akkulaufzeit ist geringer als beim iPhone, aber für Ingress brauch ich ja eh die externe Batteriebank.
Haptik und Handhabung des Gerätes ist gut, das Display ist der Hammer, und im Vergleich zu einem mir zufällig näher bekannten, knapp zwei Jahre älteren Google-Telefon hat es auch beim Ingress spielen Power ohne Ende.
Problematisch war noch die Integration ins Auto - ich höre im Auto auf längeren Strecken gerne Podcasts und will die Autobatterie statt des winzigen Handyakkus nutzen.
Komischerweise gibt es da weniger komplette Angebote als fürs Eifon - durch den proprietären Apple-Connector wämst man das Handy da drauf und hat Strom und Musik ein- bzw. ausgekoppelt und fertig (siehe mein Gejammer bei g+). Es gibt nur wenige gerätespezifische Autohalterungen fürs Nexus, die auch gleich Strom zur Verfügung stellen (gefunden hab ich genau eine, die Brodit 512482) - da verkantet nix und man muß wenigstens nicht noch das Stromkabel ranfummeln wie an diese ganzen hässlichen, schlecht passenden Universalhalterungen; aber Musik kommt da dann noch keine raus, und auf Kabelgefummel in die Kopfhörerbuchse hab ich echt gar keine Lust.
Für die Übertragung von Geräuschen aus dem Handy ins Autoradio hab ich jetzt einx A2DP-fähiges Zemex-Kastl, das sich für einen CD-Wechsler hält (preisgleiche Alternative). Es führt sich dabei so gut, daß mein Autoradio das auch denkt :-) - und der Clou ist, das es mechanisch und elektrisch die gleiche CD-Wechseler-Schnittstelle wie das Vorgänger-Kastl für das iPhone nutzt - ich mußte also nicht noch mal die ganze doofe Mittelkonsolenverkleidung ausbauen, sondern es nur anstecken, Nexus per Bluetooth mit dem Ding pairen und fertig. Ingress rödelt jetzt über die Lautsprecher des Autoradios, was schon ziemlich bedrohlich klingt. :)
Ich habe einen NFC-Tag in die Autohalterung geklebt und ich verwende Llama, damit das Handy erkennt, daß es in der Autohalterung steckt und sich entsprechend konfiguriert. Llama ist eh echt cool, um Aktionen am Handy auszulösen, es kann viel mehr, als nur Lautstärke-Profile einzustellen, sondern kann nahezu alle Software und die meiste verbaute Hardware umkonfigurieren, und das z.B. nach Gebieten, die es auch an den dort stehenden Handymasten erkennen kann (man braucht dafür kein akkumordendes GPS) oder auch am Ladezustand, an vorhandenen Wlans, Umgebungshelligkeit und und und - und kann damit BT, Screenlock, GPS, Wlan, Benachrichtigungstöne und -Vibratoren und noch vieles mehr als Aktionen für beliebige Situationen konfigurieren.
Die Migration ist damit abgeschlossen und für ein Migrationsprojekt mehr als zufriedenstellend, insgesamt eher sehr gut verlaufen. p>
Nachtrag 13.03.2013
Zum Thema Backup: Es gibt nun auch eine einigermaßen vernünftige Lösung.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
20.10.2011
22:35 Uhr Google 2factor-Auth mein Arsch
Hömma, Google,
Du bietest 2factor-Auth an, das ist schön. Aber wenn man sich entscheidet, das eigene Mobiltelefon als Token zu benutzen (mit der passenden Authenticator-Äpp), hat man an manchen Stellen schon ganz schön Scheisse am Schuh.
Die paar Anwendungen, die damit umgehen können, brauchen dann auf dem Mobiltelefon selbst mal schnell ein c&p aus der Auth-App in die Anwendung, die man benutzen will. Nervig, echt.
Aber locker Dreiviertel Deiner überall auf der Welt zusammengekauften Anwendungen können keine 2factor-Auth, und man muß sich (nach Deiner Vorstellung) dann für jede pissige Anwendung ein 'Anwendungspezifisches Passwort' bauen, und dessen 16stelligen Buchstabensalat in die Anwendung (auf Mobiltelefon, Eipäd, Standalone-Anwendung aufm Rechner, und aufm zweiten Rechner) bimseln. Habt Ihr das mal ausprobiert? Warum gibts da keinen Flansch z.B. mit einem QR-Code für?
Ok, man kann für alle Anwendungen das gleiche OTP nehmen, und nach einmal abtippen c&p machen - bei der Anzahl der Anwendungen, meiner Google-Accounts und meinen Geräten, auf denen ich diese Anwendungen benutzen will, war ich trotzdem fast zwei Stunden beschäftigt.
Warum aber zur 'ölle verliert man diese (eigentlich vielen) OTPs, wenn man ein neues Mobiltelefon bekommt? Ich verstehe, daß man die Uhr des Tokens/Telefons neu syncen muß, klar. Aber ich verstehe nicht, warum damit alle (bei mir zum Glück nur drei) anwendungsspezifischen Passwörter ungültig werden - und Deine Supportseiten behaupten sogar noch das Gegenteil (http://www.google.com/support/accounts/bin/static.py?page=guide.cs&guide=1056283&topic=1056287, Codes from Google Authenticator not workling after phone reset: >You will need to configure Google Authenticator again on your phone, but your other details will be saved. AM ARSCH WERDEN DIE GESAVED!)
Google, ich war (mal wieder) so >|< kurz davor, auf diese für mich eher marginale, aber kewle zusätzliche Sicherheit zu scheissen, und einfach wieder ein starkes Password zu benutzen.
Wenn Ihr mehr Sicherheit wollt, macht das doch bitte etwas cleverer. Nur ein kleines bißchen. Mal unter uns: Wie sollen denn bitte die Hauptadressaten von mehr Sicherheit - und zwar die, die mental nicht in der Lage sind, sich gegen Phishing und ähnliches zu schützen, diesen Weg gehen?
Macht endlich, das so geile OTP-Generatoren wie z.B. YubiKey Yubikey mit allen Google-Anwendungen funktionieren. Euer eigenes Telefon hat den passenden RFID-Leser dafür...
Macht endlich, daß sich Euer gesammter zusammengekaufter Softwarezoo vernünftig gegen Euer eigenes OAuth authentifizieren kann.
Ich kotze im Strahl mit Brocken! Und ja, ich hab nen neues Eifon. Und jetzt werde ich Siri so lange anbrüllen, bis es Deine verfickten "Anwendungsspezifischen Passwörter" tanzen kann.
Wer diesen Ausbruch diskutieren will, kann das in Google+
gerne tun.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
22.08.2011
Mit diesem Blog geht es bergab. Ich habe zwar immer noch große Lust, mich mitzuteilen, bin aber oft zu faul, mich ernsthaft hinzusetzen, und den großen, den einen, den epochalen Blogbeitrag zu verfassen - dafür mache ich das aber auch schon seit August 2002 (übrigens damals mit einer besonders räudigen Software, deswegen ist da soviel kaputt gesetztes zu finden).
Angefangen hat das Minderengagement mit der Nutzung von Twitter - mal eben eine Neuigkeit raushauen, nicht so sehr auf die Form achten - nach 140 Zeichen ist eh schluss.
Inzwischen hab ich zwei längere Artikel, die eigentich hier ins Blog gehören, auf Google+ rausgehauen, weil... - ja warum eigentlich?
- Ich glaube, es erreicht ein bißchen ein anderes Publikum, aber dann wäre es ja kein Problem, einen Artikel im Blog und auf Google+ zu veröffentlichen.
- Auf Google+ kann ich einfach so runterschreiben, ich habe nicht so viele Optionen, wie hier im Blog, hier gebe ich mir mehr Mühe, damit dauert das Verfassen auch gleich deutlich länger.
- Auf g+ gibts ein funktionierendes Kommentarsystem, im Blog nicht. Das hat damit zu tun, daß sich auf der einen Seite Google um die Authentifizierung der Kommentatoren kümmert, und ich nicht permanent Spam aussortieren muß. Andererseits geniese ich doch sehr die Interaktion mit denen, die den Schrott von mir lesen.
- und noch ein paar gefühlte Dinge mehr.
Die Artikel, die eigentlich hier ins Blog gehören, die ich aber einfach mal schnell bei g+ runtergeschrieben habe, sind: Cocktailmaschine 2.0 und mal eben Yachtrückholung.
Beide Artikel hätte ich Blog anders, ausführlicher, mit mehr Links/Bildern beschrieben - damit auch zeitaufwendiger für mich.
Außerdem stehen noch ein paar Artikel aus, wie z.B. endlich mal einer zu den Schafen[tm], dem Quadrokopter, meinem letzten Urlaub und ein Hass-Artikel zu hydraulischen Ruderanlagen im Allgemeinen. Vielleicht auch mal wieder was zum Thema Fotografie.
Aber ich komm ja zu nix - da taucht dann eben die Möglichkeit auf, mal eben was zu twittern, oder auf g+ rauszuhunzen.
Ok, ich merke es schon selbst. Ich muß wieder mehr bloggen, und dann eben bei g+ darauf verweisen, wobei ich glaube, das dem dann nicht so viele Leute (von der anderen, der Socialmedia-Seite), folgen werden, auch wenn es nur ein Mausklick ist. Oder ich muß das irgendwie besser anteasern.
Jedenfalls werde ich diesen Artikel hier und dort veröffentlichen, diskutiert werden kann ja nur auf der einen :)
Wer jetzt (auf der Blogleser/Rss-Feed-Seite) denkt google-plus? Wassn das? kann entweder wieder unter seinen Stein zurück kriechen, oder schreibt mir ne Mail, dann gibts ne Einladung - ich hab noch 150 Stück.
G+ ist ein soziales Netzwerk, es ähnelt dem bekannteren, mainstreamigeren Facebook, hat aber bei genauerem Hinsehen deutliche Unterschiede zu FB, z.B. eine (wie auch bei Twitter) asynchron ausgelegte Kommunikation: Nur weil einer mich lesen will, muß ich ihn noch lange nicht lesen (sehr praktisch). Dadurch ergeben sich Diskussionen, die sich nicht wie bei Facebook nur im Kreis drehen, weil auch Leute mit anderen Meinungen als die eigene Peergroup dazustossen. Das ist für mich das interessanteste an g+ und gleichzeitig das lame an fb. Es gibt noch ein paar mehr Unterschiede, die sind in den einschlägigen Techblogs auch durchgekaut worden und können dort nachgelesen werden.
URL der Kopie bei g+: https://plus.google.com/112989488511598991299/posts/UVoNyuo9t8w
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
06.01.2011
18:17 Uhr Und alle so - YEAH! Aufmerksamkeitsdingsonomie auf Twitter
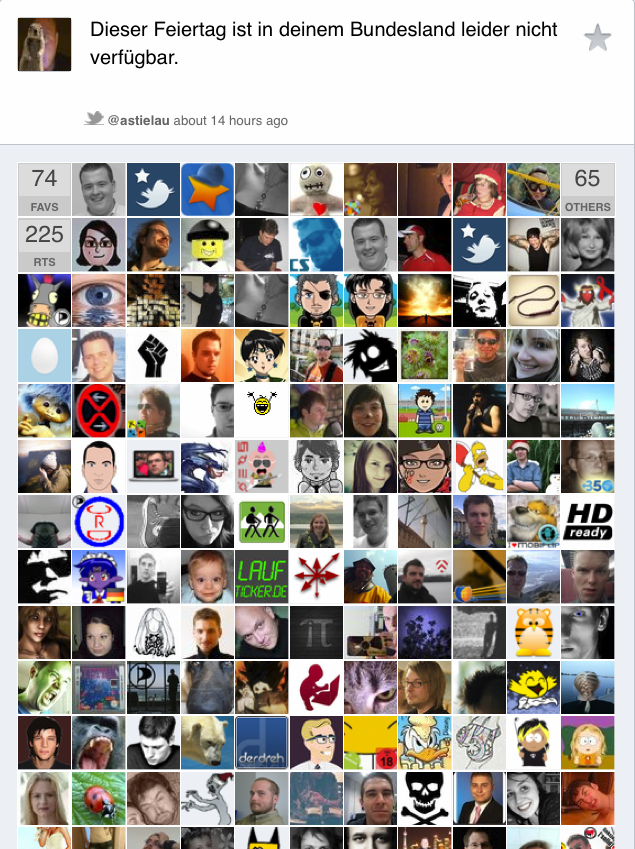
Konnte wegen Kopfkino nicht einschlafen, so las ich etwas narzistisch alte Tweets von mir.
Und da fiel mir einer auf, der heute wieder passte - also hab ich ihn noch mal hochgewürgt - Dieser Feiertag ist in deinem Bundesland nicht verfügbar (1.11.2010).
Dann ging ich ins Bett.
Heute morgen hatte ich auf einmal irre viele neue Follower. Normalerweise passiert das, wenn ich ordentlich besoffen war und dann ordentlich getwittert habe. War nicht der Fall. Hmm.
Erstmal ignoriert.
Dann im IRC:
gnihihi. 'dieser Feiertag' ist Trending Topic bei Twitter. Glückwunsch.
Hmm.
Also mal angefangen, zu suchen. Der gleiche Tweet. Aber scheinbar kommt etwas, was man nachts rauspustet, und die Leute dadurch morgens als erstes Lesen, viel besser an. Und ein paar tweetburner und gut vernetzte Kontaktnutten wie z.B. @isotopp oder @c_holler (und noch zig andere, bin zu faul zum Suchen) scheinen dann den Rest zu erledigen.
Krasser Shize. Um genau zu sein: 225 RTs, 74 FAVs. Dabei hab ich erst vor ein paar Tagen gelernt, daß es sowas wie favstar überhaupt gibt, und wozu es gut ist.
Jedenfalls ist das im Vergleich mit zertifizierten Dampfplauderen wie eben Claudius ziemlich überraschend für mich.
Außerdem bin ich überrascht, wie Twitter an diesem Punkt funktioniert. Am 1.11. gab es quasi keine Aufmerksamkeit, heute war der gleiche Spruch wirklich in den Top Tweets und in den Trending Topics. Für nix.
So, Leute, dann geht mal wieder nach Hause. Es macht mir Angst, daß mir so viele Leute folgen, die ich nicht kenne, und die nun scheinbar erwarten, daß mir gleich der näxte Qualitätstweet rausrutscht. Das ist nicht der Fall.
Lest lieber mein Blog. RSS ist nämlich gar nicht tot.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
05.07.2010
09:56 Uhr MBP Sturz - warum man Unibody mögen will

|
Wenn mal ne Fahrradtasche bei Bergabfahrt (also mit Karacho) verliert, weil der blöde Haken, der die Tasche oben am Gebäckträger hält, einfach schlapp macht, und die Tasche dann mit allem drin quer über die Brückenzufahrtsrampe kegelt, kann man dann doch ganz zufrieden sein mit der Unibody-Konstruktion eines Macbook Pro, das kann echt was ab. Das Ding war in der Tasche noch mal in so einem Neoprenschlumpf. Das Display hat dabei keinen abbekommen, das wundert mich am meisten. Auch sonst merke ich keine mechanischen Schäden, Festplatte tut noch, Displayscharnier auch. Die Kante muß ich jetzt mal vorsichtig abfeilen, ist ganz schön scharfkantig. Ich würde nun gerne mal das gleiche mit einer DELLe oder von mir aus auch mit einem Thinkpad machen. Bei der DELLe braucht man wahrscheinlich Splitterschutzausrüstung. Ne neue Fahrradtasche brauchte ich dann auch, die Hakenkonstruktion an der alten ist blöderweise vernietet. |

|
|

|
|
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
17.06.2010
22:24 Uhr Mailmigration auf Web2.0
Ich arbeite für eine Web2.0-Butze vom Feinsten - z.B. haben wir vor offiziellen EiPäd-Start so Dinger (die ich übrigens enorm unpraktisch und schwer finde) rumliegen, weil es Kunden danach gelüstet, entsprechende Ääpps zu bekommen und unsere Berater werden gezwungen, auf nem Mac zu arbeiten und überhaupt: Wo wir sind, war schon immer vorne.
Intern haben wir zur Kommunikation und Gruppengewürge nen Exchange-Server benutzt - die Ausgeburt des Bösen. Allerdings hat das Böse ziemlich gut funktioniert, vor allem in der gemeinsamen Nutzung von Kalender, Aufgaben, Mail, Adressen und soweiter mit dem entsprechenden Frontend Outlook. Fast alle, die irgendwie kein Windows hatten, waren (darüber) froh, aber gleichzeitig benachteiligt (durch Entourage aufm Mac) oder mit geringer InterInteraktiontegration mit eigenen Tools angebunden, die die unterschiedlichen Aufgaben meist besser als Outlook erledigen, aber eben nicht gemeinsam.
Mit der Zeit hat unser Exchange (mit etwa 250 realen Usern) aber immer mehr Performanceprobleme bekommen (wohl vor allem verursacht durch die stark wachsende Anzahl von mobilen Devices wie Blackberries und anderen 'push'enden Pulldiensten, die sich dann auch noch immer syncen wollten und daneben durch eine nicht so ganz den technischen Ratschlägen des Herstellers entsprechende Grundkonfiguration).
Der Exchange - die Groupwarelösung - mußte neu. Entsprechende Angebote von MickySoft-Premiumintegrationspartnern waren aber alle so irre teuer, daß relativ schnell auch in eine neue Richtung gedacht wurde, also nicht Exchange renovieren sondern abschaffen und durch was neues, irres ersetzen.
Zurück auf Anfang: Wir sind ne hippe Web-Zwo-Null-Bude, sagte ich schon. Also sind wir auch ziemlich schnell auf Googlemail gestossen. Googlemail (gmail) bietet fullservice alles an, was man normalerweise in der Unternehmenskommunikation braucht (also Mail, Kalender, Resourcenverwaltung, Instantmessenger, Adressbuch, Dateiablage, News, Websites/Wiki, ...), und man hat damit auch gleich die wirklich leidige Geschichte mit der Hardware nicht mehr an den Hacken, und es skaliert damit wie Sau.
Nach langem hin- und her hat sich unsere Geschäftsführung zu dem Schritt entschlossen, voll auf Googlemail zu setzen - in der Diskussion dahin haben eine Menge Aspekte eine Rolle gespielt, die wahrscheinlich den meisten nicht ganz unbekannt vorkommen:
Eher geschäftliche und soziale Aspekte:
- Google - die Datenkrake...
- Geben wir diese wichtige Infrastruktur wirklich aus der Hand?
- Sitzt einer von denen in Würgereichweite, wer ist da unser Vertragspartner?
- Wie gehen wir mit Vorbehalten unserer Mitarbeiter und (konservativer) Kunden um, wenn sie welche haben?
- Ändern sich unsere Prozesse? Ist das gut? Ist das schlecht? Ist das egal?
- was kostet das an Zeit und Geld, eventuell an Knowhow?
- und noch einige mehr
Eher technische Aspekte:
- Wie kann eine Migration stattfinden?
- In welchem Zeitrahmen kann eine Migration stattfinden?
- Wie läuft die Userverwaltung, was kann man automatisieren?
- Bildet das wirklich alles ab, was Exchange/Outlook konnte, was muß anders werden?
- Gibts nen Point of no return?
Eine der großen mentalen Baustellen ist bei so einem Vorhaben natürlich Google. Dem früheren 'dont be evil' Unternehmen wird - völlig zu Recht - eine starke Neigung zum Datensammeln angehängt. Völlig zu Recht, weil das nunmal der Job einer Suchmaschine ist, und auch völlig zu Recht, weil es einige Bereiche gibt, in dem sie damit in die Privatsphäre eindringen, weil sie es schaffen, Daten miteinander zu verknüpfen, die alleine kaum einen Wert haben. Ich will die Debatte um die Streetview-Wlan-Geschichte hier nicht führen (in meinen Augen ist das Hysterie, und mir wäre es lieber, Google behält diese Daten, statt diese an unsere 'Dienste' abzugeben), trotzdem bleibt natürlich die Frage, ob man der Datenkrake Tante Google wirklich seine Mails anvertrauen will.
Dazu ein paar Überlegungen: Mail ist grundsätzlich unsicher, abhörbar, und der Weg einer Mail von der Quelle zum Ziel ist weder sicher vorhersagbar noch in der Verfügungsgewalt des Senders. Alle großen Mailprovider und deren zentrale Mailhubs haben die entsprechende Infrastruktur, Mailverkehr abzuhören. Ich meine damit nicht die (ausgesetzte) Vorratsdatenspeicherung, sondern eben amtliche Schnüffelstücke entsprechend TKÜV, und was sich vielleicht so manchen noch aus eigenem Interesse und wirtschaftlichen Zwängen... - man weiß es einfach nicht.
D.h., es reicht auch bei von vertrauenswürdigen anderen oder selbst betriebenen Mailservern nicht aus, die Transportwege, soweit man sie denn im Griff hat, (also Einlieferung und die Abholung) zu verschlüsseln, sondern wirklich sinnvoll ist nur eine Ende-zu-Ende-Verschlüsselung (s/mime, pgp oder vergleichbares). Dies gilt unabhängig vom Provider. Wer jetzt einwendet, daß das den Kunden und den eigenen Mitarbeiten nicht zumutbar/beizubringen ist, muß sich da dann aber auch keine Gedanken mehr machen, wo er seine Mails lagert - ein bißchen Sicherheit gibts genau so wenig wie ein bißchen schwanger.
Es bleiben letztlich interne Mails auf selbst betriebener Infrastruktur - aber wie intern bleiben die in Zeiten von mobilen Devices wirklich und was macht man mit Mitarbeitern, die sich unabhängig von Google einfach mal so den Laptop klauen lassen? Wenn man dafür kein Konzept hat, braucht man sich um Privacy bei Google nicht so irre große Sorgen zu machen, also - dieses Problem hat man eh, und nicht erst durch Google, wenn man mal genauer nachdenkt.
Im Zuge der Migrationsvorbereitungen haben wir natürlich unseren Kunden erzählt, was wir vorhaben - witzigerweise kam da genau aus dem eher konservativen Bankenbereich ein leises 'da haben wir auch schon intensiv drüber nachgedacht'. Na dann...
Dazu kommt, daß wir hier im Vergleich zu Betrieben mit klassischer IT sehr locker mit dem Umgehen, was normale User im Firmennetz dürfen und welche Rechte sie haben - für uns ist deshalb die zu überquerende Schlucht zu googlemail sicher nicht so groß wie für klassisch-analfixierte IT-Abteilungen. Das liegt zum einen daran, daß hier IT nicht so sehr ein Werkzeug zum Abarbeiten von it-fremden Problemen, sondern zu einem sehr großen Teil Selbstzweck des Broterwerbs ist; und sicher auch, weil wir (als Firma, nicht die IT) versuchen, jeden aktuellen Hype zu verstehen um absehen zu können, ob sich daraus ein Geschäftsfeld entwickeln kann, das für unsere Kunden interessant sein könnte. Sowas funktioniert mit einem stark restriktiv organisierten Netz eben nicht.
Zum Anderen verursacht allein schon der Versuch der ernsthaften Gängelung der User echt viel Arbeit und schafft damit eine permanente Racecondition zwischen Mitarbeitern, die Grenzen ausloten und Admins, die Löcher stopfen und die Bewegungsfreiheit aller Benutzer immer weiter einengen, bis die Leute ihre IT selbst machen (lies: einen UMTS-Stick benutzen) - das kann auch nicht im Sinne der Firma sein. Wir fahren damit erstaunlich (aus meiner Sicht als damals klassisch analfixiert-ausgebildeter Admin) gut.
Genauso gibt es auch in einer Firma, die permanent nach neuem (Hype) sucht, Mitarbeiter, die konservativer gegenüber neuer Technik eingestellt sind (z.B. die Admins :-) - eine wichtige Frage ist, wie man diese sinnvoll ins Boot holt, sie dazu bringt, sich mit neuen Arbeitsmitteln zu beschäftigen und zu lernen, diese nach einer Eingewöhnung genauso effektiv zu nutzen, wie vorher Outlook - das ganze am Besten ohne riesigen Frontalschulungsaufwand.
Wir haben das gelöst, in dem wir nicht alle Benutzer auf einmal migriert haben, sondern immer mal wieder ein paar, und mit Leuten begonnen, die von sich aus erkennen liessen, daß sie große Lust darauf haben. Das gab zwar ein paar technische Probleme (die Migration von Userdaten ist ein interessantes logisches Problem, wenn man gemeinsame Resourcen wie z.B. Maildomain-Namen, Konferenzräume, Kalender benutzt, weil man da nach dem eigenen Umzug eine zeitlang zweigleisig fahren muss), aber damit hatten wir gleich von Anfang an überall im Haus Mavens für die neue Technologie, an die sich dann im Laufe der fortschreitenden Migration die jeweiligen Nachbarn wenden konnten, wenn sie ein kleineres Problem hatten. Dieser Selbsthilfe-Ansatz hat sich sehr bewährt, damit haben wir auch vielen Mitarbeitern ins Boot geholfen, die nicht so große Lust auf eine Umstellung vom Gewohnten hatten, aber letzlich doch neugierig wurden, was die anderen da so machen, und wie das genau aussieht.Empfehlenswert.
Ebenso gibt es nur sehr wenig fest vorgegebene Arbeitsabläufe - die Geschäftsführung setzt eher darauf, daß sich durch das Arbeiten mit dem neuen System (und dem alten; unser Wiki, die Fileserver und soweiter leben natürlich trotz GoogleApps weiter) sowas wie best practices entwickeln, die angemessen für die durchaus unterschiedliche Arbeitsweise der verschiedenen Teilbereiche und Teams sind.
Ein Schritt vorher haben wir mit einer kleineren Gruppe Benutzer auf einer nicht aktiv verwendeten Domain geübt, da aber vor allem technische Dinge, die dann Inhalt eines Fortsetzungsartikels werden.
Wer nach dem Lesen dieses Artikels dazu konkrete Fragen hat, schreibe diese mir, damit ich darauf eventuell eingehen kann - der zweite Teil befindet sich bisher nur in meiner wetware.
Übrigens hat Google in Europa anscheinend noch nicht so irre viele größere GoogleApps-Kunden - unser Technik-Geschäftsführer hat zu unserer Migration eine Präse zusammengetackert und diese bei Google in München und Zürich gehalten, siehe dazu im Fischmarkt Blog. Wie man so im Flurfunk hört, waren die sehr angetan. Vielleicht werden wir ja noch GoogleApps-Migration-Partner[tm] oder sowas...
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
28.01.2010
14:28 Uhr Facebook - Privacy Wahnsinn und Web2.0 Selbstmord

Da liest man nen RSS-Feed und klickert auf den Artikel, SPON poppt auf, und in der linken Spalte taucht meine Hackfresse auf. WTF?
Noch mal geguckt. Ja, its me. Mein Facebook-Account irrlichtert in einem Widget durch Spiegel Online, hat sich irgendwo ein Cookie aus meinem Browser gepuhlt und die richtigen Schlüsse gezogen.
Nach den anderen, gruseligen Erfahrungen mit FB reicht mir das jetzt, da ich sowieso keinen Mehrwert aus der FB-Community ersehen kann - ich spiele keine Browserspiele, trete auch keinen Gruppen bei, in denen man sich wünscht, anderen ihre virtuellen Bauernhöfe zu verbrennen, wenn es noch eine Farmville-Anfrage gibt, und der meiste inhaltslose Dreck, den meine 'Freunde' dort absondern, interessiert mich auch nicht sonderlich, für meine narzistischen Neigungen reichen mir Twitter und vorallem mein Blog komplett aus.
Facebook hat nach meiner Testphase von etwa drei Wochen genau ein gutes: Ich kann meine eigenen (ebenfalls inhaltsleeren) Ergüsse aus Twitter und meinem Blog automatisiert einer größeren Öffentlichkeit anbiedern, weil man Twitter und RSS-Feeds in FB anflanschen kann.
Das schlechte Gefühl, daß sich eine Facebook-App wohlmöglich automagisch auf dem mobilen Kommunikationsendgerät durch die dort abgelegten Telefonnummern frist und diese bei FB gegencheckt, ist ziemlich gruselig und den Grund (Avatarbilder für das eigene Adressbuch auf dem mobilen Telekommunikationsendgerät zu ziehen) glaube ich eh nicht.
Dann hab ich mich mal durch die Leute geklickert, die auf der gleichen Schule wie ich waren (naja, wohl eher sind), und z.B. im Slip und hautengen Oberteil auf einem Bett posieren - ohne einen Gedanken daran, diese Bilder nie wieder (nie nicht überhaupt gar nicht wieder) entfernt zu bekommen, oder Leute, die anscheinden den ganzen Tag während der normalen Büroarbeitszeiten Farmville spielen: Wollt Ihr Euch wirklich nie wieder irgendwo anders bewerben?
Ich nehm mir jetzt den Strick. Scheisse. Nicht mal das klappt, da sind gerade zu viele Selbstmorde am Laufen. Dann später, dann könnt Ihr Facebooker das hier wenigstens noch lesen, und versuchen, mich von meiner Tat abhalten!
Ja, mir
ist klar, daß ich trotzdem Web2.0 Dinge tue und stelle hier im Blog oder
per Twitter oder per Oerkswatch private Daten und
Meinungen dar, aber da bestimme ich die Granularität einigermaßen
selbst.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
07.12.2009
21:34 Uhr Will it scale? Rechnen mit der Wolke - Amazon WebServices - Teil 2

Okay, nach den einführenden Worten zu den Amazon Webservices, nun mal etwas Butter bei die Fische - Arbeiten in der Cloud.
Der erste Schritt: Eine passende AMI finden und sich so hinfummeln, wie man es gerne hätte. Das geht mit ec2-describe-images, allerdings zeigt das folgende Kommando den Irrsin des Unterfangens an:
$ ec2-describe-images -a | wc -l
970
Dafür ist dann Elasticfox ganz gut, um ein genehmes Image zu finden - oder man muß entsprechend seinen Vorlieben filtern:
$ ec2-describe-images -a|grep -i lenny|wc -l
27
Ok, wenn man nach Debian AMIs sucht, kommt man schnell auf alestic, und kann sich das dort genauer ansehen. Ich hab mich dann erstmal für
IMAGE ami-b8446fcc alestic-32-eu-west-1/debian-5.0-lenny-base-20091011.manifest.xml \ 063491364108 available publii386 machine aki-02486376 ari-fa4d668e
entschieden, also die aktuellste Version eines i386 (im Gegensatz zu amd64, eine Kostenfrage) Minimalimages (die anderen haben schnell mal nen komplettes KDE/Gnome dabei) entschieden. AMIs gibts in drei unterschiedlichen Größen, wobei sich Größe auf CPU-Büms und Plattenplatz bezieht. Zum Spielen reicht die kleinste locker aus.
Dieses AMI startet man sich:
$ ec2-run-instances ami-b8446fcc -k aleks-testkeypair RESERVATION r-c8f104bf 737588137133 default INSTANCE i-0444b873 ami-b8446fcc pending \ aleks-testkeypair 0 m1.small \ 2009-11-28T20:36:14+0000 eu-west-1a aki-02486376 \ ari-fa4d668e monitoring-disabled
Damit wird eine Instanz dieser AMI in der eigenen Umgebung gestartet, und zwar mit der Security-Group default, und meinem passenden ssh-Key in die AMI gefrickelt (das erzeugen mit ec2-add-key ist nervig und untypisch für Leute, die ssh-keygen gewohnt sind).
Nach einer Minute (oder so, kann man mit ec2-describe-instances überprüfen, das pending muß durch running ersetzt sein) ist die Instanz gebootet, und man kann sich, nachdem man in der Default-Security-Group die eigene IP freigeschaltet hat
$ ec2-authorize default -P tcp -p 22 -s 213.39.215.21/32 GROUP default PERMISSION default ALLOWS tcp 22 22 \ FROM CIDR 213.39.215.21/32
per ssh dort einloggen:
$ ssh -i .ec2/id-aleks-testkeypair root@ec2-79-125-34-231.eu-west-1.compute.amazonaws.com Amazon EC2 Debian 5.0.3 lenny AMI built by Eric Hammond http://alestic.com http://ec2debian-group.notlong.com ip-10-227-89-159:~#
Und etwas umschauen, und sich die Instanz so hinfummeln, wie man es möchte (z.B. erstmal die normalen authorized_keys hinterlegen), und die Packages installieren, die man so normalerweise braucht. Achtung, stirbt die Instanz durch Deine Dummheit, kannst Du von vorne anfangen, Änderungen werden nicht wirklich gesichert (reboot funktioniert aber ohne Gedächnisverlust).
Will man die eigene Vermackelungen für die Nachwelt oder sich selbst erhalten, muß man aus dieser Instanz wieder ein AMI machen, dafür braucht man ein S3-bucket, x509-Key und Zertifikat, dazu auch noch die AWS-ID und die passenden Keys. Die x509-pems legt man auf der Instance ab, am besten dort, wo das AMI ge'bundled' wird, weil sie damit nicht in der neu erstellten AMI auftauchen (zur Sicherheit sollte man die nicht in AMIs rumliegen lassen). Ich mache das in /mnt.
Genauer: Ich habe dafür ein Skript gebaut, daß das alles sehr exemplarisch automatisiert (und z.B. vorher Services runterfährt und ein EBS umounted (dazu später mehr))
Das Skript muß natürlich auf der laufenden Instanz ausgeführt werden, die nachfolgenden Kommandos stammen nicht aus den ec2-api-tools, sondern aus den ec2-ami-tools :)
Letzlich ist das dann auch nur ein Kommando (wenn alle Keys da sind und kein EBS mehr im Weg rumgammelt):
$ ec2-bundle-vol -d ${bundledir} -k ${pkkey} -c ${pkcert} \
-u $awsuserid -r i386 -p ${imgname}
Genauer ist das im Skript erkennbar. Das Bündel muß dann ins S3-Bucket geladen werden, dazu gibts das Kommando ec2-upload-bundle
$ ec2-upload-bundle -b ${s3bucket} -m ${bundledir}/${imgname}.manifest.xml \
-a $awsaccesskey -s $awssecretkey
Mit S3Fox kann man dann sehen, wie es im entsprechenden bucket anschwillt (das Bucket wird automatisch angelegt, wenn es noch nicht vorhanden ist).
Als letzte Amtshandlung muß man das entsprechende AMI noch im AWS registrieren - das geht wieder durch einen ec-api-tool-Aufruf, also lokal am Arbeitsplatz.
$ ec2-register ${s3bucket}/${imgname}.manifest.xml
Dieses Kommando gebiert wiederum einen AMI-Namen, den man wiederum wie oben als neue Instanz laufen lassen kann, und für die man nun seine normalen sshkeys verwenden kann (wenn man sie reingefummelt hat). Allerdings sucht man dann eben nach dem eigenen Imagenamen zur Auswahl.
Ein Problem hat so eine Instanz aber noch, sie ist ziemlich vergesslich und sie ist nicht unter einer vorher bekannten IP ansprechbar. Die Vergesslichkeit regelt man mit einem EBS - elastic block storage, die IP-Vorhersage über Elastic-IPs.
Ein EBS legt man sich einfach mit ec2-create-volume an:
$ ec2-create-volume -s 10 -z eu-west-1a VOLUME vol-aa8a6ec3 10 eu-west-1a creating \ 2009-11-28T23:19:26+0000
Die passende Zone kann man sich aus der Ausgabe von ec2-describe-instances herausfischen. Danach muß das EBS-Volume an die Instanz gebunden werden:
$ ec2-attach-volume vol-aa8a6ec3 -i i-3c3fc34b -d /dev/sdb ATTACHMENT vol-aa8a6ec3 i-3c3fc34b /dev/sdb \ attaching 2009-11-28T23:21:41+0000
Ab diesem Moment steht die Platte sdb der Instanz ztur Verfügung und kann normal partitioniert und formatiert werden.
Ein Tipp (das hat mich Tage gekostet): Wenn man in einer ursprünglichen Alestic-Instanz mit XFS rummacht, muss man zwingend Logversion 1 (mkfs.xfs -l version=1 /dev/sdb1) verwenden, sonst gibts beim ersten Zugriff ne Kernelpanic, und wenn man das Image mit den bisherigen Änderungen nicht gesichert hat, fängt man von weiter vorne wieder neu an. Die Ursache dafür scheinen Inkompatibilitäten in den von EC2 verwendeten Fedora-Kerneln mit den entsprechenden Debian-XFS-Modulen zu sein. Es gibt dazu reichlich Fundstellen im Netz.
XFS ist gut, weil man mit xfs_freeze und S3 sehr nette Backupstunts hinlegen kann, z.B. mit der Hilfe von ec2-consistent-snapshot, das auch noch ein FLUSH in den mysqld peitscht.
Ich verwende das aber bisher noch nicht, weil ec2-consistent-snapshot ein (jedesmal neues) EBS-Volume erzeigt und nicht in ein S3-Bucket schreibt. Da man den Namen nicht vorher weiß, ist ein sinnvolles Haushalten mit verschiedenen Snapshots aufwendig und letztlich durch den verbrauchten Speicherplatz teuer. Ich verwende stattdessen ein selbstgeschriebenes Skript, das mit Hilfe von s3cmd (s.u.) in ein S3-Bucket schreibt und dort Versionen mit vorhersagbaren Namen erzeugt, die es auch nach einer definierten Zeit wieder löscht.
Generell kann man sich das partitionierte EBS mounten, wie man lustig ist - ich habe mir das der Einfachheithalber erstmal unter /mnt/persistent gemounted, und alle Verzeichnisse oder Dateien, von denen ich weiß, daß sie sich unabhängig von der Maschineninstanz ändern (Home-Verzeichnisse, Datenbankspool, andere Spools, die man nicht verlieren will, Anwendungen, die unabhängig vom System gepflegt und upgedated werden, Konfigurationsdateien von Webservern, /usr/local, ... dort hin verschoben und dann ins System hineingelinkt.
Das EBS wird immer erst nach dem Booten an die Instanz gebunden, man sollte es also tunlichst vermeiden, dort zum Booten notwendige Dinge abzulegen.
Genauso wie das EBS läßt sich auch eine Elastic IP mit ec2-allocate-address bereitstellen und dann mit ec2-associate-address an eine Instanz binden. Das geht auch schon während des Bootens, also direkt, nach dem ec2-run-instances den Instanznamen preisgegeben hat.
Ich habe dafür ein Skript, daß eine passende AMI auswählt, mit den passenden security-groups startet, die IP dranklatscht, und immer wieder überprüft, ob der Status pending in den Status running gewechselt ist - wenn ja, wird das EBS attached.
Services, die auf Informationen auf dem EBS zugreifen, starten also nicht automatisch, bzw. brechen mit einer Fehlermeldung weg, wenn man das vorher weiß, kann man sich das aber entsprechend hinfummeln.
Die eigene Instanz läuft also - wichtig ist, immer daran zu denken, daß man nach Umbauten am System, die nicht im EBS zu liegen kommen, ein neues AMI erzeugen muß, um diese Änderungen für die Zukunft zu erhalten.
Es gibt die Möglichkeit, eine laufende Instanz direkt aus den AWS heraus zu überwachen, und bei bestimmten Triggern weitere, gleiche Instanzen zu starten - da fängt das Wolken erst richtig an. Damit habe ich aber noch nicht viele Erfahrungen, das reiche ich in einem gesonderten Artikel nach.
Praxis
Naja, es verhält sich wie ne normale Maschine :-)
Zum Arbeiten mit S3 hab ich noch s3cmd gefunden, damit kann man von der Shell aus in einem (oder mehreren) S3-Buckets herumfuhrwerken, das läßt sich aus meiner Perspektive in Skripten besser handhaben als als die im S3-Guide vorgestellten php, java, ruby, python, c++ und sonstigen Programmierbeispielen, um mal eben ne Konfiguration im Backup zu sichern und ähnliches. s3cmd funktioniert auch gut aus ec2-Instanzen heraus. Debianer sollten nicht die paketierte Version verwenden, die kann z.B. kein -r (recursive).
$ s3cmd ls 2009-11-25 09:11 s3://s2-master-img $ s3cmd put Desktop/jahrbuch2009_export.pdf s3://s2-master-img Desktop/jahrbuch2009_export.pdf -> s3://s2-master-img/jahrbuch2009_export.pdf [1 of 1] 13526575 of 13526575 100% in 206s 64.01 kB/s done
Zur Praxis schreibe ich später noch mal was, wenn ich mehr rausgefunden habe.
Was kostet der Spaß?
Kurz: ich weiß es noch nicht genau.
Lang: Das AWS-Bezahlsystem ist eigentlich simpel, aber kompliziert, weil jeder kleine Furz einzeln abgerechnet wird.
Eine kleine EC2 Unix Instanz kostet z.B. in Europa USD 0.095 pro Stunde, dazu kommt Datenverkehr (USD 0.10 per GB rein und USD 0.17 per GB raus (wird billiger mit mehr Traffic). Dazu kommt EBS mit USD 0.11 pro GB im Monat für die Größe des Devices und USD 0.11 für 1.000.000 I/Os...
Okay, ich kann mir darunter nicht so irre viel vorstellen, Du auch nicht? Dafür gibts den Simple Monthly Calculator - der nicht so ganz simpel ist, will er doch Daten haben, die ich aus der hohlen Hand nicht einfach so weiß. Einfach mal selbst probieren...
Der dritte Teil wird etwas auf sich warten lassen, probiert einfach mal selbst damit rum.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
28.11.2009
23:05 Uhr Erfahrungen im Rechnen mit der Wolke - Amazon WebServices - Teil 1

Okay, wenn der pointy-haired boss das so will, dann machen wir das mal. Seit ungefähr 4 Wochen vor dem passenden Dilbert beschäftige ich mich mit Cloud Computing, und versuche herauszufinden, ob das für unsere Firma eine brauchbare Möglichkeit ist. Genauer, ob es für uns interessant ist, entsprechende Resourcen zu nutzen, weil sie angeblich schnell und auf den Punkt verfügbar sind, sehr gut skalieren und erst genau im Moment der Nutzung Kosten verursachen.
Ziel der Untersuchung ist einer der ganz großen Cloud Computing Anbieter, Amzon. Genauer AWS - Amazon WebService. Das gute daran: Jeder, der einen 'normalen' Amazonk-Account hat, kann darüber eventuelle Experimente abrechnen.
Da das für die meisten Leser ein relativ neues Feld sein wird, gibts erstmal ein paar AWS-Konzepte erklärt. AWS bietet sehr viel mehr als ich hier darstelle - siehe die Produktseite, ich beschränke mich hier erstmal auf EC2 und S3.
Grob gesagt stellt Amazon EC2 (Elastic Compute Cloud) die eigentlichen virtuellen Maschinen-Resourcen zur Verfügung. EC2 ist auf gute Skalierbarkeit und pay-per-compute ausgerichtet. D.h., es ist sehr einfach, zusätzliche, identisch konfigurierte Instanzen auch kurzfristig zu den vorhandenen dazuzustarten. Abgerechnet wird streng nach Verbrauch (CPU, Traffic, Plattenplatz, genutzte IPs usw). Was man nicht nutzt (und deswegen abschaltet), zahlt man auch nicht. Eine gute Einführung in die Konzepte gibts im EC2 GettingStartedGuide und die eigentliche Bedienungsanleitung im EC2 UserGuide. Da, wo mein Geschreibsel ins Nebulöse abgleitet, ist man beim Nachspielen gut beraten, diese Dokus zu lesen (die gibts auch als html und auch diverse weitere, gute Doku).
Amazon S3 (Simple Storage Service) bietet eine einfache Mögllichkeit, beliebige Daten im Netz vorzuhalten. S3 wird über eine eigene API angesprochen und kann nicht direkt als Filesystem in eine EC2-Instanz gemounted werden. Auch S3 wird streng nach Verbrauch (verbrauchter Plattenplatz, Traffic) abgerechnet.
Alle AWS Komponenten laufen selbst auch in Clouds, die Amazon als Regions bezeichnet. Derzeit gibt es zwei Regionen, eine an der US-Ostküste, eine in Europa. Wichtig ist hier nur, daß in der Regel alle Services in der gleichen Region läufen müssen, wenn diese in einem Projekt gemeinsam genutzt werden sollen. Ein Umzug in die andere Region ist möglich, aber umständlich.
Die konkrete Anzahl von Rechenzentren hinter diesen Regionen ist erstmal verborgen und unwichtig.
Im EC2 gibt es ein paar tolle Marketingschwurbel-Begriffe, die ich trotzdem verwende, weil ich sonst andere, die ebenfalls EC2 verwenden, nicht verstehe.
- Die wichtigste Resource ist dabei ein AMI - Amazon Machine Image. Amazon (und auch andere) hält eine große Anzahl von unterschiedlichen AMIs zur Benutzung bereit, darunter befinden sich unter anderem auch Linux- und Windows-Images. Diese Images kann man sich so anpassen, wie sie für den eigenen Einsatzzweck am besten geeignet sind, d.h., die entsprechenden Packages installieren, die man immer benötigt, User und Keys hinterlegen usw. Hat man sich aus einem Default-AMI ein entsprechendes laufendes System zusammengeschustert, kann man dies in ein neues AMI überführen und entsprechend im AWS (genauer im S3) ablegen. Je nach Wunsch kann man dieses Image öffentlich zur Nutzung bereitstellen oder es nur selbst nutzen. Ein AMI ist grundsätzlich vergesslich - wird eine laufende Instanz abgeschaltet, gehen ALLE Änderungen, die seit dem Starten vorgenommen wurden, verloren, ebenso gehen alle dyanmisch zugewiesenen Resourcen verloren, wie IP-Addresse, ssh-hostkeys, gemountete externe Filesysteme. Dies betrifft allerdings keine Reboots. Aus diesem Grund ist an einigen Stellen ein Umdenken erforderlich, um die nichtvorhandene Persistenz des Filesystems durch andere Konzepte zu ersetzen.
- Elastic IP - AWS verwendet für neu gestartete AMIs eine interne, nicht routingfähige RfC1918 IP-Adresse, die nicht persistent ist. Auf diese interne IP wird von außen über eine ebenfalls nicht persistente routingfähige IP genattet. Damit ein Angebot auch bei wechselnden AMI immer unter der gleichen IP (und damit letztlich einem DNS-Namen) erreichbar ist, gibt es das Konzept der Elastic IP. Damit kann eine IP unabhängig von laufenden AMI definiert werden, diese IP hat einen festen, einigermaßen vorhersagbaren DNS-Namen, und diese IP kann an eine gerade laufende AMI gebunden werden. Da die Elastic IP auf eine beim Start eines AMI nicht vorhersagbare IP genattet wird, wird ein anderer Weg benötigt, ein AMI intern persistent ansprechen zu können (Klassiker: Datenbank-Verbindung auf einen anderen Host). AWS verwendet ein DNS-System, das intern in der AWS anders auflöst als bei einer Anfrage aus dem Internet. Fragt man von Intern nach dem PTR der Elastic IP, bekommt man die interne IP des AMI, auf das gerade die Elastic IP gemappt ist. D.h., man kann den PTR als Hostnamen in Konfigurationsdateien sicher verwenden.
- EBS - Elastic Block Storage ist ein in ein AMI hineinmountbares Blockdevice, das unabhängig von einer AMI existiert und damit als Persistenzlayer dienen kann. Mit EBS ist es möglich, Daten über einen Neustart hinaus zu erhalten. Das Blockdevice kann frei konfiguriert und z.B. mit einem Dateisystem versehen werden. Es ist möglich, mehrere EBS an ein AMI zu binden, allerdings ist es nicht möglich, ein EBS an mehrere AMI gleichzeitig zu binden. EBS verfügt über die Möglichkeit, snapshots vom Device zu erstellen, um es zu sichern oder es zu klonen und anderen AMI zur Verfügung zu stellen. In meinem Test-Projekt ist in jede laufende AMI-Instanz ein EBS als Partition gemounted und alle erhaltenswerten Daten (z.B. Userhomes, Anwendungsdaten, Datenbank-Daten, per AMI individuelle Konfigurationsdaten, ... sind entsprechend in die vorgesehenen Stellen im Filesystem des AMI hineingelinkt. Dabei darf man es nicht übertreiben - ein Linux bootet z.B. logischerweise nicht ohne ein lokales /etc. :-)
- Die Security Groups stellen die Firewallkonfiguration des EC2 dar. Um für unterschiedliche Instanzen unterschiedliche Zugriffsmöglichkeiten zu ermöglichen, gibt es ein entsprechendes Gruppenkonzept. Das ist pille palle, das einzige, auf das man achten muß: Eine AMI kann nur VOR DEM START einer oder mehrerer Security-Gruppen zugeordnet werden.
Eigentlich kommt man mit dem oben dargestellten Möglichkeiten gut zurecht, allerdings nur, wenn man keine selbst vergurkten AMIs verwendet :-)
Die sinnvollste Möglichkeit, größere Datenmengen (z.B. eben AMIs) unabhängig von einer laufenden Instanz in der Amazon Wolke abzulegen, bietet S3 - Simple Storage Service. Zum S3 gibts auch wieder diverse Dokumentationen, Einstieg ist wieder der entsprechende GettingStartedGuide.
S3 ist nicht direkt mit mount als klassisches Filesystem mountbar, sondern über eine REST- bzw SOAP-API, für die es in jeder aktuell gängigen Programmiersprache Beispiele zum Anflanschen eigener Software gibt. Aktuelle Software zum Handhaben von Dateien (z.B. cyberduck aufm Mac, S3fox für Firefox und eben EC2-AMIs) hat entsprechende Schnittstellen implementiert.Informationen werden in sogenannten buckets organisiert und bieten eine relativ granulare Möglichkeit der Zugangsberechtigungssteuerung.
Die AWS nutzen eine mehrstufige Authentifizierung, die sich auch je nach Komponente unterscheidet.
- Für den Login in die AWS-Management-Webseite wird als Userkennung eine Emailaddresse und ein Password benutzt (die Amazonk-Buchladenkennung).
- Für die direkte Arbeit mit EC2 und S3 benötigt man wiederum unterschiedliche Credentials, diese werden im AWS-Account generiert bzw. können dort ausgelesen werden.
- Um einen Service anzusprechen, benötigt man die Accesskeys
- Um AMIs zu bauen, benötigt man zusätzlich x509-Keys
- Um sich auf Amis einzuloggen noch zusätzlich ssh-keys.
Neben den oben genannten Tools für S3 gibt es noch ein paar weitere, mit denen man sich an die Möglichkeiten von EC2 rantasten kann:
- Die AWS Management Console ist per Webbrowser erreichbar, damit kann vorallem EC2 administriert werden. Von der Bedienung eher unhandlich, Benutzer, die Firefox verwenden, sollten lieber Elasticfox und S3Fox verwenden.
- Elasticfox ist ein Plugin für Firefox und ermöglicht alle üblichen Operationen an EC2 per Webinterface. Achtung, die in Elasticfox verwendeten Tags sind LOKAL (werden nicht in die Cloud geschrieben) für den User, dem Firefox gehört - aus diesem Grund taugen die Tags auch nicht zur Namensgebung, wenn man im Team arbeitet.
Seine ganze geballte Kraft entfaltetet sich aber erst, wenn man die ec2-api-tools einsetzt, die man einigermaßen vernünftig skripten kann. Die ec2-api-tools sind in java geschrieben, und durch clevere wrapper für so ziemlich jede Betriebssystemsumgebung geeignet, wo man ein java und eine shell draufgewämst bekommt. Meine Beispiele beziehen sich auf nen Unix, genauer nen Mac. Das geht aber auch gut unter Windows.
Wenn man sich an die traditionellen Regeln für shell-Betrieb hält, und alle einigermaßen konstanten Parameter als Umgebungsvariablen exportiert (
$ set|grep EC2 EC2_CERT=/Users/alesti/.ec2/cert-test.pem EC2_HOME=/usr/local/ec2-api-tools EC2_PRIVATE_KEY=/Users/alesti/.ec2/pk-test.pem EC2_URL=https://eu-west-1.ec2.amazonaws.com
), sind die Tools angenehm zu nutzen, ansonsten hat man schnell ekelhafte Kommandowürmer:
ec2-describe-instances -K ~/.ec2/pk-test.pem -C ~/.ec2/cert-test.pem \ -U https://eu-west-1.ec2.amazonaws.com i-04f60b73
gegen
ec2-describe-instances i-04f60b73
Das Ergebnis ist in beiden Fällen (auf zwei Zeilen):
RESERVATION r-b07398c7 \ 358240633166 \ testgroup,default INSTANCE i-04f60b73 \ ami-370e2543 \ ec2-79-125-2-112.eu-west-1.compute.amazonaws.com \ ip-10-224-99-79.eu-west-1.compute.internal \ running \ 0 \ m1.small \ 2009-11-24T16:56:00+0000 \ eu-west-1a \ aki-02486376 ari-fa4d668e \ monitoring-disabled \ 79.125.2.112 \ 10.224.99.79
Das kann man gut mit shell-Mitteln auseinanderfummeln und weiter verwursten.
Soviel erstmal zu den Basics, im folgenden zweiten Teil folgt dann der praktische Umgang mit AWS EC2 und S3.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
30.10.2009
17:12 Uhr OSMC - Öberwachong öber all!

Und ich meine diesmal nicht Kameras und Schleierrasterfahndung, sondern die Beobachtung von Netzen, Rechnern und darauf laufenden Diensten auf Funktion - ein (leider) wichtiger Teil meines Jobs.
Gestern und vorgestern gab es dazu eine Konferenz in Nürnberg, die Open Source Monitoring Conference. Dort bin ich mit einem zappeligen Kollegen hingefahren, auf dem Fußweg vom Bahnhof zum Hotel sind wir dann auch erstmal direkt durchs Rotlichtviertel gestolpert - im Hotel gabs dann lecker Abendessen und es war ziemlich voll - eine trotz Wirtschaftsdepression ausgebuchte Konferenz, schon mal nicht schlecht.
Nun aber eher zum Inhalt, und was ich mitgenommen habe.
Leider gibt es die meisten Folien noch nicht online, ich erweitere diesen Artikel entsprechend, wenn die Folien verfügbar sind.
Jetzt wirds technisch, nicht computeraffine Leser können also aufhören, es verstehen zu wollen oder gleich aufhören, es zu lesen.
Ich schreib auch noch am Wochenende was neues, ich hab nämlich ein neues Spielzeug bekommen.
Der international agierende Großheilige St. Isotopp eröffnete den einen Track (es gab zwei parallele) mit einem Vortrag zum Thema Monitoring MySQL (was sich dann gleichzeitig als MySQL-Tuning-Vortrag herausgestellt hat).
Kristian hat seinen Vortrag mit einer (für mich) Banalität eröffnet, und zwar mit der Feststellung, daß es unterschiedliche Gründe für 'Monitoring' gibt, und das meist jeder, den man fragt, was anderes darunter versteht. Und zwar mindestens
- Operations (also Fehlererkennung und Handling),
- Infrastruktur-Entwicklung (Sizing, zukünftige Entwicklungen abschätzen),
- Entwicklung (Fehler in Software erkennen und in zukünftigen Versionen ausbauen, neue Features kontrollieren),
- Verfügbarkeitsauswertung (SLA Compliance).
Jede dieser Monitoringarten hat unterschiedliche Anforderungen in Bezug auf Zweck, Messtechnik, abzulieferndes Ergebnis, mögliche Latenz und Verfügbarkeit - aus diesem Grunde solle man es eher vermeiden, die Daten für alle Monitoring-Typen gemeinsam zu erheben oder zu verarbeiten. Das ist für mich banal, weil wir das sowieso so handhaben - wir erfassen mit unserem Operations-Monitoring (zum Vergleich: Wir setzen Nagios zur Überwachung von etwa 550 Hosts und 2400 Services ein) keine Performancedaten, sondern machen dies z.B. mit Munin. Natürlich erfasst unser Nagios auch Performancedaten (das machen viele Checks automatisch), aber wir werten diese nicht via Nagios aus.
Mir war nicht klar, daß andere das in extremer Weise tun, das stellte sich erst im Laufe der Konferenz heraus. Genauso war mir nicht klar, daß es sinnvoller ist, das bewußt zu trennen (wir machen das wohl auch, weil es bei der Einführung von Nagios (damals noch Netsaint) noch nicht vorgesehen war). Wenn man mittels Nagios auch Daten für die Performanceauswertung erfassen will, muß man natürlich auch entsprechende Checks einrichten, die dann dem Operating aber auch nicht mehr Informationen zur Fehlerbeseitigung liefern als die eh schon vorhanden Checks, dafür aber auf dem Nagiossystem ordentlich Last und vor allem gewaltige Datenmengen erzeugen.
Dieses für mich 'Nichtproblem' zog sich durch die ganze Konferenz, meist verbunden mit dem Wunsch, dem Webinterface von Nagios mehr Konfigurationsmöglichkeiten, Views und Personalisierung zu verpassen - was mir total wumpe ist. Das Webinterface von Nagios ist häßlich, aber es erfüllt seinen Zweck. Etwas, das mich nachts um 3:48 Uhr weckt, muß nicht schön sein, sondern ich muß erkennen können, was Phase ist und ich muß das Gebimmel zielgerichtet abschalten können. Das lösen wir durch sinnvolle Checks und Abhängigkeiten und nicht durch Web2.0-Grafik. Das sieht natürlich anders aus, wenn man schöne Grafiken über z.B. die Auslastung von Mailqueues direkt im gleichen Tool haben will.
Ebenso scheinen viele aus dem Grund der Weiterverwurstung von fürs Operating erzeugten Daten die Datenbankschnittstelle von Nagios zu verwenden - und dort alles hineinzuballern, was man zumindest fürs Operating nach drei Tagen gar nicht mehr braucht. Ein ähnliches Problem scheint es auch beim (kommerziellen) MySQL-Enterprisemanager zu geben, dies hat bei Kristian (als Ex-MySQLler) dazu geführt, noch während der Konferenz in das NDO-Schema hineinzukriechen und ein paar Ideen dazu zu veröffentlichen. Ich hoffe, das lesen mal die richtigen, z.B. die Jungs vom Icinga-Team.
Der Rest von Kristians Vortrag taugt dafür, ein Gefühl dafür zu bekommen, welche Parameter man für ein Operating-Monitoring gerne überwachen möchte und MySQL zu tunen, also grundsätzliche Performanceprobleme zu verstehen und dem Datnbanksystem dann auf die Sprünge zu helfen. Guckt Euch die Folien an, es ist für mich als Nicht-DBA ne Menge Stoff dabei, von dem man zumindest mal gehört haben sollte.
Als nächstes habe ich einen Vortrag über SNMP gehört (net-snmp: The forgotten classic) - allerdings hat das bei mir nicht so richtig gezündet, weil es um wirklich classic snmp generell ging und nicht so sehr eine sinnvolle Nagiosintegration. Ich finde SNMP zum Glück meist vermeidbar, und vorallem sollte man das meiner Meinung auch immer tun, wenn das zu monitorende Gerät die Möglichkeit bietet, anders an Informationen zu kommen. Inzwischen ist das bis auf bei wenigen Switchen und ähnlicher Hardware problemlos möglich.
Im Anschluß gab es einen Vortrag zu einer Migration von Tivoli auf Nagios in einer wirklich großen (>11.000 Hosts) und heterogenen Umgebung (bei Audi).
Interessant zu sehen, welche Prozeduren dort eine Rolle spielen, aber vorallem hat mir der lakonische, stark dialektgefärbte Sprachstil von Eric Pfaller gut gefallen.
Nicht verstehen kann ich allerdings, wieso man dort statt nrpe (damit kann man Testkommandos auf Remotesystemen absetzen) check_ssh einsetzt - der ssh-Verbindungsaufbau ist verschlüsselungstechnisch um Größenordnungen teurer als der von nrpe. Scheinbar haben die das auch schon bemerkt, deswegen wird mit selbstgefrickelten Cachingmechanismen gearbeitet (anscheindend werden mehrere Checkanfragen und deren Antworten gesammelt und dann gemeinsam übertragen - ... Latenzen...).
Daneben verwendet Audi zur Verwaltung und Erzeugnung der Nagioskonfiguration einen LDAP-Server, der die entsprechenden Templates vorhält. Das hat allerdings einen sinnvollen aber ebenso perversen Touch und ist damit interessant :-)
Audi öffnet übrigens automatisiert für jeden hard-status CRITICAL nen Ticket. Toller Spaß.
Allerdings fand ich die Ankündigung zum Vortrag Application monitoring - Bridging the gap, der parallel zur Vorstellung des LDAPs als Backend für die Objektkonfiguration laufen sollte, interessanter, so daß ich dann doch dahin gegangen bin - ich war auch nicht enttäuscht.
Michael Medin, der in seiner not-so-spare time für Oracle arbeitet, ist ein guter Redner und inhaltlich ging es am Beispiel der jmx-console um Anwendungsmonitoring. Wir setzen jmx-monitoring ein, allerdings nicht im Operating, sondern zum Debugging, Development und allgemeinen Beobachten von Java-Anwendungen.
Medins Kernforderung: Redet miteinander, redet mit den Entwicklern! Stellt den Entwicklern Möglichkeiten zur Beobachtung ihrer Anwendungen zur Verfügung, in der Regel wissen diese nämlich weder, wie sich Ihre Anwendungen unter dem Eindruck von echten Benutzern verhalten, noch, daß es diese (feine) Möglichkeit bei Java-VMs, .NET und anderen Sprachen gibt. Gerade, wenn wie bei Java eine komplette VM hochgerissen wird, ist es sehr interesaant zu sehen, wie die garbage collection (nicht) funktioniert, wie viele Sessions der Datenbankconnector hält und was sich so im Heapspace tummelt.
Dabei ist noch das für mich neue jmx4perl aufgetaucht, daß anders als unsere Lösung keine java-libs zieht und damit auch keine eigene java-vm bootet.
Als letzten Vortrag am Mittwoch habe ich mir die Präse vom Icinga-Team gegeben. Icinga ist ein Nagios-Fork (Gründe für den Fork), die Core Teammitglieder sind anscheinend alle aus der Gegend und im Dunstkreis des Veranstalters Netways angesiedelt. Der Vortrag war von der Darbietung her erfrischend unprofessionell (aber nicht vom Inhalt) - durch den ständig wechelnden Vortragenden (und den Kampf darum) wurde es nicht langweilig.
Auch hier ging es (wie in den von mir eher nicht besuchten Vorträgen) zum großen Teil um die Darstellung und den Umgang mit den Ergebnissen von checks. Icinga bietet dafür in Zukunft ein sehr frei konfigurierbares Webinterface an, so daß sich damit jeder Betrachter seine spezifischen Views zusammenbauen kann - das neue Webinterface ist in PHP, damit ergeben sich dann die im web2.0 üblichen Dinge wie Ajax-Suche usw..
Icinga versucht, abwärtskompatibel zu Nagios zu bleiben (so lange es geht), gleichzeitig benötigt Icinga auf jeden Fall die Datenbankanbindung. Die Entwickler arbeiten daran, diese auf standard SQL zu bekommen, um andere DBRMS (PostgreSQL und Oracle) anbinden zu können. Daneben sind die Jungs dabei, eine universelle Schnittstelle zu entwickeln.
Die Präsentation hat deutlich gemacht, daß das Icinga-Team mit Hand und Fuß plant und dann entwickelt, und nicht im allgemeinen Fork-Chaos irgendwo Funktionen dranfrickelt - das gibt ein gutes Gefühl auf die folgende Entwicklung. Seit der Konferenz ist 1.0RC1 verfügbar.
Der 'gesellige Abend' war ok, allerdings waren die Tische etwas zu groß und die Mukke etwas zu laut, um sich in Ruhe austauschen zu können. Ich bin von dort dann trotz der weiteren Strecke zum Hotel gelaufen (gestützt durch Kristians und mein Handy-GPS - wie haben wir das nur früher hinbekommen) - wenn der Konferenzort auch noch der Schlafort ist, ist das zwar morgens sehr bequem, und man kann in Schluffen zum Vortrag, aber man bewegt sich quasi gar nicht mehr.
Der nächste Morgen begann mit check_mk als Alternative zu NRPE der sich im Nachhinein als mein persönliches Highlight herausstellende Vortrag. Wieder ein komplettes Konzept, bei dem deutlich wurde, daß der Entwickler nicht hirnlos angefangen hat, herumzubasteln, sondern vorher über eine Art Architektur für ein Tool nachgedacht hat.
check_mk ermöglicht durch die Verlagerung der nrpe-Konfiguration auf den Nagioshost eine Nichtkonfiguration auf dem zu checkenden Client - mit dem Pferdefuß, daß dies nur für stark normalisierte Standardsystemparameter funktioniert.
Die Vorteile des Konzeptes: Irre schnelles Ausrollen auf einer großen Anzahl von sehr heterogenen Clients, sehr einfache Möglichkeit der Überprüfung, ob evtl. Dinge dazugekommen sind, die man auch überwachen möchte, automatische Erstellung von 0815-Nagios-Konfigurationsdateien, irre Performance - weil check_mk einfach nur den Daemon auf dem Client anpiekst, und der alles auskotzt, was er weiß. D.h., es gibt nicht für jeden einzelnen Check eine Kontaktaufnahme.
Die Nachteile des Konzeptes: Im wesentlichen funktioniert das nur für wellknown Standardsystemparameter, es ist also super, um Eisen zu überwachen. Es ist ungeeignet, um sehr individuelle Checks zu verarbeiten, also genau das, was Anwendungsüberwachung eigentlich ausmacht. Bei nrpe kann ich einfach alle individuellen Anwendungschecks in die nrpe_local.cfg schreiben, diese global verteilen und via Nagios-Konfiguration jeweils pro Host genau die ansprechen, die ich dort brauche - bei check_mk muß man das dann anscheinend doppelt konfigurieren, also auf dem Client ins Scriptsverzeichnis kippen und auf dem Server entsprechend nach konfigurieren.
Insgesamt aber eine interessante Sache, die ich auf jeden Fall ausprobieren werde. Bei kurzem Nachdenken fallen mir sofort noch einige andere mißbräuchlinge Dinge ein, die man mit der Inventarisierungsfunktion von check_mk tun kann - z.B. per nmap alle Hosts vom Typ X (sagen wir mal Xen-VM) finden und dann mit check_mk -L trübertackern und die Systemdaten wegschreiben, nachdem man ins Skriptverzeichnis für Debian-Kisten z.B ein 'dpkg -l'-Aufruf gesetzt hat... Außerdem scheint es auch ein logwatch-Flansch zu geben, da kann man diese Daten auch schön weiterverarbeiten.
Über das Gespräch mit Mathias Kettner hab ich dann den nächsten Slot verpaßt, aber das war auf der einen Seite die übliche Stockebrandt-IPV6-kommt-jetzt-bald-wirklich-Gedächnisveranstaltung und auf der anderen was über NConf, ein grafisches Enterprisekonfigurationstool. Nach (sehr kurzem) Nachdenken kommt man eigentlich darauf, daß zumindest ich in einer Enterprise-Umgebung Nagios-Dateien lieber maschinell (aus LDAP, per python-Parser, klassischem Makefile oder sonstirgendwie) aus dem svn lutsche und generiere denn über ein GUI zusammenklicke, aber da sind die Geschmäcker anscheinend verschieden.
Im Anschluß gab es eine Vorstellung des Monitorings in einer Enterprise-Umgebung, und zwar der von LindenLabs 2nd Life (auch deutlich über >10.000 Hosts).
Dort ist man den sonst üblichen Weg, die mit Nagios erzeugten Daten in einen grafischen Aufbereiter zu kippen, genau umgekehrt gegangen - so werden dort die Daten aus Ganglia, einem freien Monitoringsystem speziell für große Grids und Clustersysteme, an Nagios weiterverfüttert, um den Performance-Problemen mit z.B. aktiven Checks aus dem Weg zu gehen. Interessanter Ansatz, für das OP-Monitoring braucht man ja in der Regel nur einen Teilsatz der im grafischen Verlaufsmonitoring eh vorhandenen Daten.
Leider findet man auf der Ganglia-Webseite im ersten Schritt keine brauchbare Doku, ich hab das erstmal nicht weiter verfolgt.
Ganz zum Schluss gab es dann noch einen Vortrag zum Nagios-Benachrichtigungssytem, der zwar meiner Meinung nach sehr gut war, aber aufgrund des Themas wohl eher als einführender Vortrag an den Beginn der Veranstaltung gehört hätte.
Für die meisten wohl eher nix neues dabei, trotzdem fundiert und vor allem didaktisch sauber aufbereitet.
Zusammenfassung
Das Hotel, Unterbringung und das ganze Drumherum war super. Der Service war so gut, daß er fast schon genervt hat - wenn man beim letzten Bissen seinen Teller nicht mit Messer und Gabel verteidigt hat, wurde er einem sofort weggerissen und man mußte sich nen neuen holen.
Die Themen der Konferenz haben mich etwa zur Hälfte interessiert, und es waren zwei parallele Tracks. Leider waren ab und zu Sachen, die mich interessierten parallel. Wahrscheinlich läßt sich das nicht vermeiden, wenn man Wert darauf legt, daß es immer einen deutschen und einen englischen Vortrag parallel gibt, um sowohl internationale Besucher als auch (ältere) deutsche Besucher entsprechend abzuholen.
Die Besucherstruktur fand ich für eine OpenSource-Konferenz eher ungewöhnlich, nur wenig bekannte Gesichter, die auch nur wenig auf die bekannten Gagstarter (... you are currently dying...) reagierten. Nach meinem Eindruck viele Leute, die ohne großen OSS-Hintergedanken Nagios einsetzen (weil es augenscheinlich am meisten bäng for the bugs gibt) oder beim Veranstalter Kunden sind und nur darüber auf OSS-Konferenzen auftauchen. Nichtsdestotrotz haben sich viele interessante Gespräche und einige Kontakte ergeben.
Aus den Gesprächen nebenbei hat sich immer wieder ergeben, daß viele Besucher Mehrfachtäter sind und sich oft als Community-Members aus den Nagiosbenutzer-Selbsthilfeforen (z.B. Nagios-Portal oder Monitoring Exchange) kennen.
- Ich nehme mit, daß opensource monitoring in der Regel wie 'nagios' ausgesprochen wird. Hoffentlich ändert sich das bald auf 'icinga'.
- Ich nehme mit, daß ich mich mit check_mk beschäftigen werde und wahrscheinlich auch mit jmx4perl.
- Ich nehme mit, daß die Probleme, die die meisten Konferenzteilnehmer drücken (grafische Aufarbeitung, Konfiguration und Auswertung) für uns keine sind.
- Ich habe den Eindruck, daß ich bei einem ernsthaften Problem mit Nagios die vorhandenen Foren und Boards vergessen kann, zumindest, wenn ich eine Antwort will.
- Ich nehme einige Antworten auf Fragen mit, die ich nie gestellt hätte.
Insgesamt hat es sich auf jeden Fall gelohnt, an der OSMC teilzunehmen.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
11.07.2009

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hä? Ok, connectionsharing klingt noch bescheuerter. Heute gehts um das Teilen von Internetzugangspunkten mit anderen.
In Firmen ist ja sowas durchaus üblich und praktisch - das gemeinsame interne Netz hat einen Ausgang, und dort wohnt das Internet.
Privat gibts das ebenfalls als default, wenn man sich eine wie auch immer technologisch umgesetzte Internetanbindung mietet.
Allerdings ist so eine private Leitung in der Regel nicht immer komplett ausgelastet, und so sind die Endpreise wohl auch kalkuliert. Das Unternehmen FON setzt mit seiner Geschäftsidee schon seit längerem genau an diesem Punkt an, und bietet preisgünstige (um nicht subventionierte zu schreiben) und technisch relativ hochwertige Wlan-Router an, die man sich als Mieter einer Internetverbindung anschaffen kann, um erstens zuhause kabellos zu surfen (das ist nix neues) und zweitens die vorhandene und meist pauschal bezahlte Leitung mit anderen gemeinsam zu nutzen.
Diese 'anderen' können dies tun, wenn sie entweder selber bei sich zuhause Bandbreite über einen FON-Router zur Verfügung stellen, oder entsprechende Vouchers bei FON kaufen.
Selber Fonero werden ist günstig - die einfachste Fonera (so nennen die ihre Router) kostet 20 Euro und ist ein ziemlich vollwertiger Wlan-Router.
Die Sache hat allerdings mehrere Haken:
- Obwohl ich Fonero (Mitglied) bin, hab ich noch nie das Wlan eines anderen Mitglieds genutzt - es ist einfacher, einfach den UMTS-Stick zu zücken und inzwischen auch nicht mehr teuer. Das stellt das Geschäftsmodell von FON generell in Frage, obwohl ich auf meiner fonera schon ab und zu fremde Nutzer habe. Um FON-Spots zu finden, kann man die entsprechenden Karten benutzen.
- Die Nutzungsbedingungen der meisten Internet-Zugangsanbieter schliessen diese Art der Nutzung aus (dazu unten mehr)
- Es besteht die Gefahr (wie bei allen eher offenen Wlans), daß über die eigene Leitung im Netz scheisse gebaut wird, und das die Scheisse erstmal auf einen selbst zurück fällt - bis die Strafverfolgungsbehörden verstanden haben, daß die Scheisse von anderen (in diesem Fall einigermaßen ermittelbaren Personen) stammt, ist erstmal alles, was mit Strom funktioniert, in der Aservatenkammer.
Ein Zugangsanbieter in Deutschland hat gegen eine kommerzielle Mitnutzung des von ihm bereitgestellten Privat-Kunden-Internetanschlusses auf Unterlassung wegen unlauteren Wettbewerbs geklagt und gewonnen, die Berufung ist nun vom OLG Köln zurück gewiesen worden - das betrifft auch das Geschäftsmodell von FON. Witzigerweise hat die neueste release candidate Firmware nun einen Schalter, mit der man das öffentliche FON-Signal abschalten kann - Zusammenhang?
Daneben ist es natürlich einfach möglich, undercover Internet mit Freunden, Nachbarn und Bekannten zu sharen, indem man einfach den entsprechenden Wlan-Schlüssel weitergibt. Dies ist - ebenso wie die Nutzung von FON - in den meisten Zugangsanbieter-AGB verboten, weil dies die Kalkulation des auflaufenden Traffics schwieriger macht und man dafür lieber auf Geschäftskundentarifbasis abrechnen möchte - nichts desto trotz macht das wohl jede WG so.
Neben dem Festnetz-DSL-Sharing wird es zumindest für mich immer wichtiger, auch unterwegs Internet zu haben und dieses auch mit anderen zu teilen. Typische Einsatzszenarien sind Treffen an Orten, an denen es kein Wlan gibt, dies aber für die Arbeitsgruppe zur Arbeit notwendig ist. Ich hatte dieses Problem zuletzt bei der Blackflag-Aktion auf der Kieler Woche und auch auf dem Bundesparteitag der Piratenpartei, bei dem ich mit in der Orga gesteckt habe.
Auf der Kieler Woche war unser Büro in einem Auto mit Drucker und allem, wir hatten sogar nen 12V-220V-Wandler - aber kein gemeinsames Netz. Auf dem BPT gab zwar Internet, aber kein für die Orga abgetrenntes, einigermaßen sauberes (Mitgliederdaten und so...).
{kind=link}
Auch auf anderen, 'fliegenden' Treffen ist dies zunehmend ein Problem - immer mehr Arbeitsmaterial liegt im Netz und nicht lokal vor, und oft ist es nicht ausreichend, wenn dann einer Netz hat (via UMTS-Modem im Handy oder UMTS-USB-Stick oder oder).
Die einfachste Möglichkeit ist es natürlich, einen Rechner mit UMTS-Stick durchlaufen zu lassen und diese Verbindung über Wlan für andere freizugeben. Die aktuellen UMTS-Sticks bzw. die damit gebündelte Software behindert genau dies allerdings ziemlich eindrucksvoll - an dem Web'n'Walk-Manager aufm Mac bin ich nach 20 Minuten Gefrickel nicht mal eben so vorbeigekommen (der schaltet stumpf das Wlan ab bzw. in eine Umgebung, in der es kein Wlan gibt - clever).
Die zweite Möglichkeit ist es, ein Handy zu benutzen, über dessen Modem eine UMTS-Verbindung aufgebaut wird und diese dann zu teilen. Geht mitm Mac und z.B. einem Nokia 6233 ziemlich gut - allerdings muß man dann, wie oben auch, den Rechner und das Handy laufen lassen und kann das Handy nicht mehr mit sich rumtragen und beim Telefonieren ist die Chance hoch, daß die Verbindung abkackt.
Ich hab mich deshalb etwas umgetan in der Richtung wlan2umts-Router. Am Markt gibts so einiges, vom einfachen, vom Provider gebrandeten umts2wlan-Router (einschlägig: web'n'walk-Router in etwa 20 Bauformen, aber meist ohne Ethernet und von der Software eher unkonfortabel) bis zum schusssicheren Industrial-Design. Das meiste ist mir entweder zu fipsig oder viel zu teuer.
Dazwischen liegen z.B. die Router von Linksys / Cisco, die einen recht ordentlichen Eindruck machen und mit einem befummelbaren Betriebssystem ausgeliefert werden, und einer der Router von FON, und zwar die Fonera 2.0.
Da ich zufällig so ein Gerät habe, mußte ich das latürnich ausprobieren, das Feature tut nur mit bestimmten usb-Sticks (Kompatibilitäts-Liste), der hier rumliegende T-Bim-Stick (Option irgendwas) tat natürlich nicht, aber einer von fonic (wie passend der Name) tat nach etwas Gefrickel mit Firmware-Updates einwandfrei.
Die Fonera als wlan2umts-brigde zu nutzen, hat noch ein paar Vorteile, an die USB-Schnittstelle kann man einen USB-Stick (oder Platte) hängen, dieser ist per smb aus dem internen Netz mountbar - so hat man gleich noch einen Fileserver für die Arbeitsgruppe dabei und muß nicht immer das eigene Laptop laufen lassen; über den Ethernet-Port kann man weitere, nicht wlan-fähige Geräte anschliessen, Drucker und so Zeug.
Allerdings braucht man dafür zwingend Netzstrom und so ganz spontan ist das auch nicht mehr, schnell hat man wieder einen Haufen Geklöter mit dabei - Fonera, Netzteil, einen kleinen Switch, Netzteil, Kabel usw.
Für spontanes Internetsharing hab ich gerade JoikuSpot
entdeckt - das macht aus einem Symbian-Mobiltelefon eine
wlan2umts-Bridge. Funktioniert super, aber man sollte das Netzteil fürs
Handy in der Nähe haben, das ist die erste Anwendung die ich kenne, bei
der man konfigurieren kann, bei welchem Akkuladezustand die Anwendung
abschaltet :-)
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
25.06.2009
18:43 Uhr Silberfisch mit Licht

Mein tapferes Macbook (eins der ersten in schwarz, von Juni 2006) hat nun fertig, da es aus der Apple-Versicherung Care&Protection raus ist und nach drei Jahren wohl auch abgeschrieben ist.
Apple hat mit dem Care&Protection in diesem Fall wohl eher drauf gezahlt, neben dem dritten Akku hatte es auch schon das dritte Topcase (Oberschale mit Keyboard, Trackpad und drumherum), das Mainboard wurde einmal erneuert und das optische Laufwerk wurde auch getauscht.
Ok, ich schleppe das Teil auch immer (ich meine immer) mit mir rum, da gibt es schon mal die eine oder andere mechanische Belastung.
Dafür weiß unser Apple Händler aber auch meinen Namen und wie ich meinen Kaffee am liebsten trinke. Schon fast etwas zu devot.
Das neue Spielzeug hat nun Unibody (das Gehäuse ist aus einem Stück Alu genagt) und ist wie mein aller erstes Apple-Laptop (huhu eventmops!) wieder silbern.
Die Migration hat unglaublicherweise dank TimeMachine nur knapp zwei Stunden gedauert - Timemachine-Platte anschliessen, Backup auf den neuen Rechner spielen (das dauert etwas), Apple-Update-Service durchladen, rebooten, fertig.
Ok, fast. Die Dinge, die nicht im Backup waren, mußte ich noch rüber-rsyncen, aber dann war es fertig. Ich bin wirklich begeistert, dachte schon, ich muß mich wieder tagelang durch das Neugerät fressen und UIDs anpassen, Ports neu bauen usw.
Das Neue ist spürbar schneller (ok, drei Jahre CPU- und Grafikentwicklung sind nicht umsonst), so schnell, daß nun GoogleEarth ruckelfrei auch auf dem externen 24"er läuft und unser (LaTeX)-OP-Handbuch (1200 Seiten, zwei Durchläufe, dann als pdf öffnen) in 20 Sekunden baut.
Ansonsten begeistert mich gerade die automatische Tastaturbeleuchtung. Das ist so ähnlich wie eine automatische Wischiwaschi-Schaltung im Auto. Wenn die zum falschen Moment losgeht (Waschanlage, z.B.) ist gleich der Arm ab. Bin gespannt, was das Equivalent dazu ist...
Das Trackpad ist größer und tastenlos, die Applefraggles haben es aber geschafft, einen echten, mechanischen Klick einzubauen, damit stimmt die Klickhaptik wieder.
Den Akku kann man nicht mehr tauschen, dafür hält er angeblich bis zu 7 (sieben!) Stunden. Wenn es sechs sind, wäre ich auch ziemlich zufrieden.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
27.03.2009
17:32 Uhr SD Memory Card Recovery
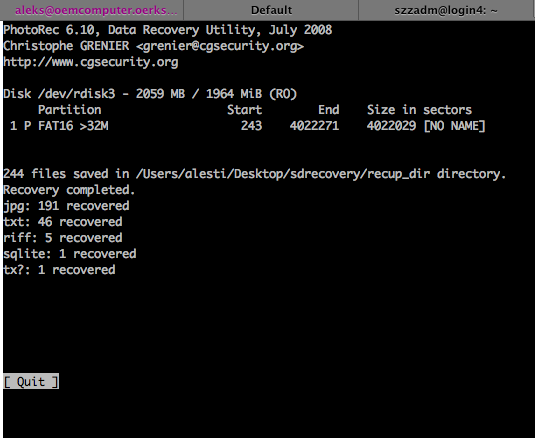
Nach dem Keiner will Backup, alle wollen Restore Artikel neulich nun ein Restore aus der Praxis.
Wie Nils neulich auch schon hat ein Freund von mir seine SD-Karte in einer Kamera geshreddert.
Ohne bei obigen Artikel nachzusehen, bin ich bei einer Suche nach entsprechenden Recovery-Tools wohl zufällig auf das gleiche Werkzeug gestossen und habe es ausprobiert.
PhotoRec, weil es OSS ist und nicht wie viele andere (shareware-)Werkzeuge die Bilder nur anzeigen aber nicht speichern kann - dafür müßte man die Software erst registrieren. Obwohl man da dann wenigstens nicht die Katze im Sack kauft.
Außerdem arbeitet es auf der Komandozeile und unter so ziemlich jedem handslüblichen Betriebsystem und mit so ziemlich jedem handelsüblichen Dateisystem (auch HFS+, ext4 und andere, jenseits des Mainstreams).
Von der SD-Karte von Andy, die mit den typischen BSD-Unix-Dateisystemtools nichts mehr zu entlocken war, hat photorec noch 191 Bilder runtergekratzt - wesentlich mehr, als der aktuelle Besitzer darauf gespeichert hat :-)
Nach dem bewußten, mehrfachen Überschreiblöschen ist allerdings dann
auch für photorec nix mehr zu holen.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
24.03.2009
22:43 Uhr Netzwerkkarte für Gamer

Also so richtig schlimm kann ja die Wirtschaftskrise doch noch nicht sein. Solange es Meldungen wie diese hier gibt, und sich dann das Produkt auch verkauft, wird alles gut.
Eine Netzwerkkarte speziell für Gamer. Soso. Mit Display auf der Karte und einer verspielten Klingonenfingermesserapplikation daran.
Die Karte zeichnet sich dadurch aus, daß sie zeitkritische Datenpakete bevorzugt ausliefert. Verstehe. Drücke auf den Feuerknopf (und das unehrenhafte seitliche Wegducken) werden nicht mit GE, sondern mit c ausgeliefert - wie praktisch - zumindest bis zum DSL-Modem.
Und wie es sich für Gamer-Zubehör gehört, hat sie 256 MB RAM. Nochmal, es handelt sich um eine NETZWERKkarte, nicht um eine Grafikkarte.
Nebenbei kann die Karte selbst noch VoIP selbst verarzten. Nicht nur schnell schiessen, auch schnell sprechen. Würde sagen, damit ist die Zielgruppe eventuell überfordert. Achja, beim Thema Actionshooter-Gamerbashing: Titanic hat da so einen Verdacht.
{kind=link}
Wenn man die Karte gamertypisch übertaktet, kann man bestimmt auch 1,2 Gigabit rauskitzeln.
Uns geht gar nicht schlecht, wir jammern nur auf hohem Nivea.
[Kategorie: /computers] - [permanenter Link] - [zur Startseite]
21.02.2009
10:26 Uhr Keiner will Backup, alle wollen Restore

Bei mir hat es nun das zweite Mal in unmittelbarer Nähe zur Wohnung gebrannt, und der Gedanke, bei einem Feuer einen Haufen Daten zu verlieren, weil ich meine artig und einigermaßen regelmäßig angelegten Backups zu Hause aufbewahre, nervt.
Aus diesem Grund hab ich mich noch mal mit dem Thema auseinandergesetzt - bisher benutze ich zur Sicherung meiner privaten Daten zu Hause mehrere Strategien gleichzeitig:
- Texte, Skripte und anderes weitestgehend textbasisiertes Zeug liegt sowieso versioniert in SVN-Repositories.
- Fotos (das sind aktuell so 70 GB) liegen auf derzeit drei externen Platten.
- meine Linux-Rechner rsyncen sich gegenseitig, was die wichtigeren Dinge angeht, die nicht in meinem $HOME liegen (wenn sie denn mal gleichzeitig laufen).
- auf dem Mac benutze ich iBackup, was für alle typischen Programme entsprechende Extentions bereithält, um auf einigermaßen vernünftige Art an die Konfigurationen, Lizenzen und so weiter zu kommen.
- Wirklich richtig wichtige Dinge wie ssh- und gpg-Schlüssel hab ich auf einem verschlüsselten USB-Stick.
Das SVN-System ist für nichtbinäre Dateien mein Favorit, weil es eben neben Backup gleich eine feine Versionsverwaltung mitliefert, und man von überall aus an die Daten rankommt, weil die SVN-Repositories, die ich nutze, übers Internet erreichbar sind. Für die, denen svn (subversion version nagetier) unbekannt ist: Das ist ein einigermaßen modernes Versionkontrollsystem, um auf einigermaßen durchschaubare Art und Weise mit vielen Leuten gleichzeitig an einem Softwareprojekt zu arbeiten, ohne sich dabei ständig durch eigene, für andere unvorhersehbare Änderungen gegenseitig in den Fuß zu schiessen, weil es z.B. möglich ist, sich widersprechende Änderungen sinnvoll zu behandeln. Weiteres unter der o.g. URL.
Für Fotos und andere binäre Dateien (ich hab kaum Musik und keine Filme) ist svn eher unbrauchbar, weil svn versucht, den Unterschied in einer Datei zwischen der aktuellen und der letzten Revision wegzuschreiben - bei Dateien, die aus nichtlesbaren Zeichen bestehen, ist das schwierig und so wird dann die gesammte Datei immer wieder komplett in das Repository geschrieben, wenn sie verändert wurde (jaja, da gibt es Zwischenformen, ich weiß). Aus diesem Grund habe ich die Fotos, wenn sie von der Speicherkarte der Kamera auf den Rechner kommen, auf einer externen Platte liegen (auf dem Laptop ist nicht genug Platz). Wenn ich an den Bildern rumgemurkelt habe oder neue dazu kommen, synchronisiere ich diese Platte jeweils einzeln mit zwei weiteren externen Platten (einigermaßen regelmäßig, nicht täglich). Dafür benutze ich rsync mit --no-perms-Option, weil eine der externen Platten ein kleines NAS-System ist, daß leider komische Vorstellungen von Unix-Gruppenrechten und umasks hat. Damit nun nicht jedesmal aufgrund der unterschiedlichen Dateirechte an allen Dateien geschraubt wird, dieser Kniff.
Durch die drei Platten und unterschiedliche Technologien (Ethernet, usb, firewire) habe ich eine relativ hohe Chance, das mir nicht alle Daten gleichzeitig verloren gehen. Ich bin auch paranoid genug, die beiden Sicherungsplatten nicht gleichzeitig anzuklemmen und sie sind von unterschiedlichem Anschlußtyp und Hersteller.
Außer, ich bin nicht zu hause und habe (was nur sehr sehr selten passiert, wenn ich weiter als bis zum Bäcker gehe) meinen Laptop und die fragliche externe Platte nicht in der Tasche und die Hütte brennt ab/Flugzeug fällt ins Haus/Waschmaschine der Übermieteren platzt/lokal begrenzter EMC-Schlag/blablafaselrabarber/$DEFAULTKATASTROPHE.
Musik - also, ich meine bezahlte Musik - würde ich wohl ähnlich sichern. Mir ist Musik nicht wichtig genug, geraubte besorgt man sich im Fall des Falles eben neu.
Konfigurationsdateien und anderen Krempel, der sich nicht richtig fürs svn eignet, synchronisiere ich mittels eines von Ray übernommenen und aufgebohrten rsync-Backup-Skriptes, das in mehreren Generationen ebenfalls auf eine der oben genannten Platten schreibt. Der Trick zum Platzsparen dabei ist, sich seit dem letzten Backup nicht veränderte Dateien nicht erneut auf dem Backupmedium abzulegen, sondern einfach nur aus dem aktuellen Generationsverzeichnis einen Hardlink (gnu: cp -l) zu legen. Das Skript sichert auch automagisch mysql-Datenbanken, ldaps und was eben so anliegt an Daten, die man nicht unbedingt plain auf die Platte rotzen will.
Aufm Mac benutze ich eben iBackup, das hat ne nette GUI, auf der man sich zusammenklickern kann, was man gerne gebackupt haben möchte. Es kann Netzlaufwerke und lokale Platten bespielen, oder per ssh/rsync Daten remote einkippen - aber es kann nicht incrementell arbeiten (oder ich hab das nicht gefunden). Ich will aber nicht zweimal die Woche 40GB Daten wegschreiben, sondern höchstens einmal alle zwei Monate und in der Zwischenzeit eben immer nur den Diff aufheben. Dazu kommt, das iBackup unglaubliche Resourcen verschlingt - eigenlich kann man das nur nachts laufen lassen.
Toll an iBackup ist hingegen, daß es für fast alle Programme, die man so auf dem Mac benutzt, passende Plugins hat, um auch die Konfiguration vernünftig zu sichern.
Zu dem USB-Stick schreib ich jetzt mal nix, das ist wohl ein extra-Kapitel.
Was alle obigen Backups (mit Ausnahme von svn) als Problem haben: Man muß es auch regelmäßig machen. Bei Dateien aus dem SVN-Repository macht man ja sowieso reflexhaft ein svn commit hinterher.
Als ich den Mac von Tiger auf Leppat umgestellt habe, hab ich das vorallem getan, weil mich Timemachine interessiert hat (und ich wollte Java 1.6 - beides erstmal ne Pleite...). Timemachine ist die Applelösung fürs Desktop-Backup. Sie ist unauffällig und macht, was sie soll - so las man.
Also damit erwartungsfroh rumgespielt (ganze 15 Sekunden) und festgestellt, daß das Mistding nur auf lokal angeschlossene Platten schreiben kann, nicht aber auf Netzlaufwerke (auf Remotemacs hingegen geht - das Problem scheint zu sein, das Timemachine die Platte selbst richtig formatieren muß, evtl. mehr Inodes als üblich? Evtl. geht eine lokal erstmalig genutze Platte später auch übers Netz, ich werde das probieren). Anscheinend konnte Timemachine auch keine anderen, externen Laufwerke sichern. Mein Interesse war also sofort und weitgehend erlahmt, ich hatte auch gerade keine Platte zur Hand, die ich mal eben formatieren konnte (Timemachine will eine eigene Partition haben).
Nach dem zweiten Brand hab ich mich jetzt noch mal mit dem Thema auseinandergesetzt, und eigentlich ist Timemachine eine geile Möglichkeit, sehr regelmäßig und ohne großen persönlichen Einsatz Backups zu bekommen:
Ich habe durch Ausprobieren und Versuch und Irrtum herausgefunden (also erst hab ich meine Hangarounds gefragt - die benutzen es, wußten aber erstaunlich wenig darüber, was geht und nicht geht), das Timemachine neben den eigentlichen Daten auch sämtliche Verwaltungsinformationen zum Backup auf die angestöpselte Platte schreibt (macht ja auch Sinn für ein bare metal restore). Das bedeutet, man kann mehrere, komplett von einander unabhängige Backups auf unterschiedliche Platten an unterschiedlichen Orten machen.
Ich habe mir zwei einfache externe USB-Platten gekauft, und eine davon steht nun zuhause und die zweite in der Firma. Steckt man eine dieser Platten an, merkt Timemachine das ohne weiteres Zutun (wenn man eine Platte das allererste mal ansteckt, muß man 'Volume wechseln' klickern, um die Platte/Partition erstmalig zu initialisieren und das erste Vollbackup einzuleiten) und macht ein inkrementelles Backup zu dem letzten, was sich auf der Platte befindet, drauf.
Wenn man das oft macht, kostet das kaum Zeit und wenig neuen Platz - wenn man ein paar Spezialisten von Backup ausnimmt, z.B. die Entourage-Datenbank. Die hat anscheinend das gleiche Binärdaten-Problem wie oben svn mit Bildern - aber das ist mir wurscht, ich brauche das nur als Verbindung für Termine in der Firma, im Notfall kann sich Entourage diese Daten auch alle neu besorgen. Eventuell bessert Apple da ja auch noch nach.
ich habe so also zwei aktuelle Backups an unterschiedlichen Standorten - und es sichert meine externe Platte mit den Fotos auch noch gleich mit.
Im Filesystem der Timemachine-Partition sieht es ziemlich genau aus wie auf dem Filesystem der rsync-Konstruktion von oben. Anscheinend nutzt Apple da auch irgendein rsync auf Drogen, das z.B. auch die schrägen zusätzlichen Dateiattribute auf HFS sauber einfängt.
Da kann man sich dann auch mit dem Finder oder auf der Shell die Dateien rausklauben, die man mit einem älteren Stand benötigt, aber nun kommt Apple - Apple wäre nicht Apple, wenn es nicht ein grafisch überlegenes 3D-Restore-Frontend (nämlich eben die Zeitmaschine) gäbe, mit der man wie im modernen Finder in der Diaschauansicht durch die Zeit browsed und sich die Dateien rauspickt, die man braucht. Spaceig, siehe Teaser.
Bare metal restore geht auch: Platte anstecken, von DVD booten, Timemachine-Restore auswählen. Ich wollte das heute probieren, in der Firma war aber gerade kein gleiches Macbook frei, aber ich werde das die Tage nachholen.
Macweenies: Das wollt Ihr auch. Und vorallem probiert das Restore aus, bevor Ihr es braucht.
Alle anderen: Macht irgendwie Backups, auch von Euren privaten Arbeitsplätzen. Macht sie möglichst automatisch und kontrolliert diese paranoid und zwanghaft. Ich glaube, das ist das einzige, was vor karpotter Hardware schützt. Murphy guckt ja schon, wo er zuschlägt.
Und man möge mir die tonnenförmige Verzeichnung des Fotos (ja, es ist eins, Screenshot geht nicht, wenn sich der Mac zu 3D aufplustert) verzeihen. Besser kann meine Kompakte das nicht.